
이전 글에서 로컬 모델을 내 PC에서 사용하는 방법과 비용 벤치마크를 다룬 적이 있었다. 다만 대형 모델들을 개발 환경과 함께 로컬에서 동시에 돌리기에는 VRAM을 비롯한 하드웨어 부담이 컸다.
무료 모델은 사용량이 제한되어 있고, provider 상태나 시간대에 따라 응답 속도와 안정성이 출렁인다. 유료 모델처럼 꾸준한 연결성이 보장되지 않고, 무료 티어의 Rate Limit 장벽도 생각보다 낮다.
아예 안 쓰자니 아깝고, 메인 파이프라인에 그대로 넣기에는 애매한 상태였다.
조금 더 안정적으로 무료 API를 활용할 수 있는 구조를 고민하던 중, oh-my-free-models라는 오픈소스 프로젝트를 발견했다.
oh-my-free-models(omfm)는 여러 무료 모델 후보를 OpenAI-compatible 방식으로 묶어 하나의 엔드포인트로 호출할 수 있게 해주는 프록시 도구다.
이렇게 해서 OpenRouter, NVIDIA, Groq를 같은 방식으로 비교하고, 하나의 로컬 프록시 엔드포인트 뒤에서 사용할 수 있는 환경을 만들었다.
OpenRouter만으로는 조금 아쉬웠던 이유
처음에는 최소 금액인 10달러만 충전해 두고 OpenRouter만 직접 연결해서 사용하는 방식도 검토했다.
특정 provider 하나에만 의존하기보다는 OpenRouter, NVIDIA, Groq를 후보군으로 묶어두고 상황에 따라 더 나은 경로를 선택할 수 있는 구조가 필요했다.
이때 omfm을 로컬 프록시 서버로 띄워두면 내 코드는 외부 인프라의 복잡한 분기 처리를 신경 쓸 필요 없이, 로컬에 떠 있는 엔드포인트 하나만 바라보면 된다.
baseURL: http://127.0.0.1:4567/v1
model: omfm/fast기존 메인 서버 경로와 겹치지 않도록, omfm은 별도의 포트인 4567로 분리해 띄웠다.
무료 API 쪽에 문제가 생겨도 기존 메인 경로까지 같이 흔들리지 않게 하기 위해서다.
omfm 설치와 실행
{
"scripts": {
"omfm": "omfm start --port 4567 --daemon"
}
}pnpm omfm이렇게 구성해 두면 pnpm omfm 실행 한 번으로 4567 포트에 OpenAI 호환 프록시가 백그라운드 daemon으로 구동된다.
API Key는 프로젝트 밖에 둔다
OpenRouter, NVIDIA, Groq의 액세스 키들은 개별 프로젝트 내부의 .env 파일에 넣지 않고, omfm 고유의 전역 설정 경로에 둔다.
~/.oh-my-free-models/.envOPENROUTER_API_KEY=sk-or-...
NVIDIA_API_KEY=nvapi-...
GROQ_API_KEY=gsk_...omfm doctor문제가 없다면 provider별로 local-env, prefix ok 메시지가 출력된다.
외부 provider의 키 관리나 무료 모델 카탈로그 갱신 같은 운영 자산은 omfm 레이어 뒤로 넘겼다. 프로젝트 코드에서 외부 API 키를 분리할 수 있어서 .env도 깔끔하게 유지된다.
모델 선택과 Latency 측정
인터랙티브 터미널 UI인 omfm model을 통해 어떤 무료 모델을 활성화할지 스페이스바로 선택할 수 있다. 툴 내부적으로 정의된 그룹별 묶음 선택도 지원한다.
omfm model --group fast내 코드단에서는 실제 호출되는 모델 ID를 일일이 추적할 필요 없이 "model": "omfm/fast"만 지정하면 된다. 어떤 provider의 어떤 모델이 지금 가장 상태가 좋은지는 프록시 레이어에서 처리한다.
omfm model --group fast --best --json실제 연결 모델 및 벤치마크 결과
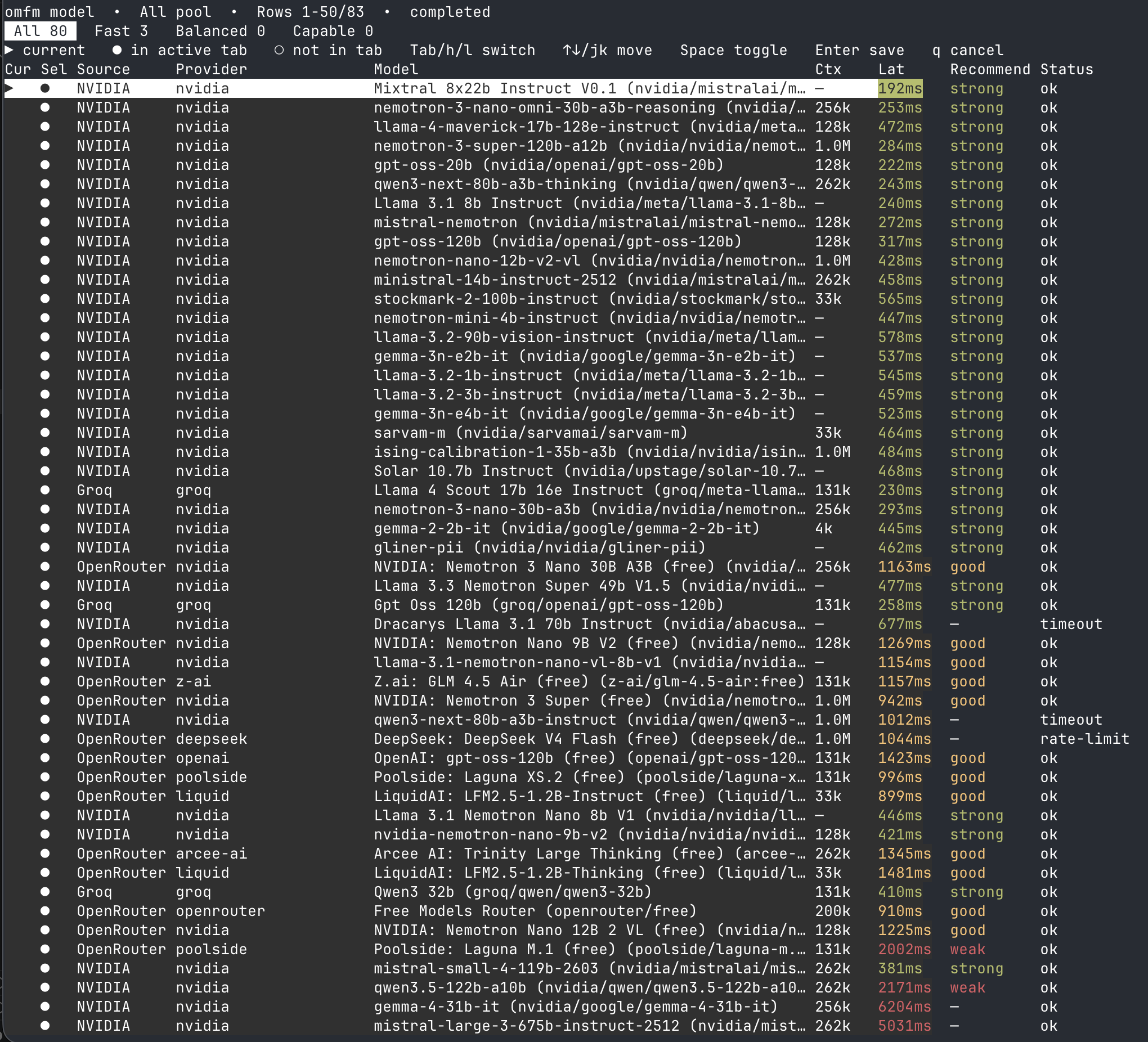
수집된 지표를 보니 provider별 특징이 꽤 뚜렷했다.
1. OpenRouter: 넓은 모델 풀, 그러나 아쉬운 레이턴시와 안정성
다만 Latency 지표를 보면 대다수 모델이 900ms ~ 1,400ms대에 머물렀고, 특정 provider에서는 2002ms(weak)로 튀거나 rate-limit이 관측되었다.
2. NVIDIA / Groq: 직접 엔드포인트의 빠른 반응 속도
NVIDIA와 Groq의 직접 엔드포인트는 체감상 확실히 가벼웠다.
- NVIDIA는 체급이 큰
Mixtral 8x22b에서도 약 192ms 수준의 Latency를 기록했고,Llama 3.1 8b라인은 240ms 내외의 쾌적한 상태를 유지했다. 다만 100B 이상 초거대 모델 풀에서는 간헐적으로timeout이 발생하는 모습도 보였다. - Groq 또한 새로 추가한
Llama 4 Scout 17b가 약 230ms, 대형 모델인Gpt Oss 120b가 약 258ms 수준을 기록했다.
omfm은 모델별 상태와 Latency 데이터를 기반으로 더 나은 후보를 고를 수 있게 해준다. 여러 무료 모델을 하나씩 직접 붙이는 것보다 운영 부담을 줄일 수 있었다.
일일 제한 모델은 10분이 아니라 하루 동안 제외하기
툴을 그대로 가져다 쓰기에는 한 가지 걸리는 부분이 있었다.
단순히 분당 요청 수(RPM) 제한에 걸린 거라면 10분 뒤에 다시 시도하는 방식이 괜찮을 수 있다.
하지만 Groq과 NVIDIA 무료 티어에서 더 문제가 되는 것은 일일 제한(Daily Limit)이다.
그 결과 Groq이나 NVIDIA가 하루 단위 제한에 걸려도 10분 뒤에 다시 찔러보고, 다시 429를 맞고, 또 10분 쉬는 식의 비효율적인 재시도 루프가 생길 수 있었다.
스크린샷에서 일부 라우트가 계속 rate-limit 상태로 남아 있는 것도 이런 장기 제한 상태와 관련이 있어 보였다.
이 문제를 줄이기 위해 오픈소스 소스코드를 직접 수정하는 패치를 적용했다.
구조가 직관적이어서 변경 자체는 어렵지 않았다.
- 기존 로직: 에러 캐치 시 재시도 대기 시간을 일괄적으로
10분상수로 처리한다. - 수정 패치: 에러 바디의 메시지를 파싱하여 일일 한도 초과 키워드(TPD, Quota 등)가 감지되면 하루 단위 쿨다운을 적용한다.
그 동안에는 OpenRouter 등 다른 살아있는 경로를 우선 사용하게 되므로, 불필요한 재시도와 지연을 줄일 수 있다.
OpenAI-compatible endpoint로 호출하기
import OpenAI from "openai";
const client = new OpenAI({
apiKey: "local", // 로컬 프록시이므로 임의의 더미 키 입력
baseURL: "http://127.0.0.1:4567/v1",
});
const response = await client.chat.completions.create({
model: "omfm/fast",
messages: [{ role: "user", content: "ping" }],
});
console.log(response.choices[0]?.message?.content);실전 응용: 토이 프로젝트에서 Claude Code API 트리오 구성하기
이렇게 구축한 무료 프록시와 로컬 환경을 결합하여, 실제 토이 프로젝트의 Claude Code 개발 에이전트 환경에 연동해 사용하고 있다.
Claude Code 환경 설정 또는 호환 CLI shim 래퍼에서 요구하는 대표적인 체급 트리오인 opus, sonnet, haiku 엔드포인트를 다음과 같이 각기 다른 성격의 인프라로 매핑해 두었다.
참고로 OpenAI 규격의 모델 endpoint를 Anthropic 형식으로 연결하려면, Anthropic proxy를 지원하는 라이브러리를 함께 사용하면 편하다.
opus— 고지능 추론 엔진: Crof AI의 GLM 5.1
sonnet— 범용 고속 프록시: omfm/fast
haiku— 초고속 가성비 엔진: 로컬 머신의 Gemma 4
이 함수 단위 테스트 코드 짜줘.
스타일 가이드에 맞춰 UI 컴포넌트 리팩토링해줘.
간단한 타입 오류 수정해줘.이 구간에 omfm/fast를 끼워 넣으면 메인 상용 모델의 사용량을 아끼면서도 충분히 빠른 응답을 받을 수 있었다.
월 10달러 고정 비용에 세 가지 엔진을 붙여, 토이 프로젝트를 꽤 가성비 있게 굴리고 있다.
이 문제를 제대로 다루려면 단순히 레이턴시가 빠른 모델끼리만 그룹을 묶으면 안 된다.
예를 들면 이런 식이다.
capable-1m : 긴 문맥 유지가 필요한 롱 세션용
fast-128k : 가벼운 단발성 핑퐁용
fast-32k : 짧은 코드 보조와 단순 질의용정리
무료 모델을 메인 파이프라인에 직접 붙이는 건 여전히 불안하다.
이번 구성은 그 불안함을 완전히 없애는 게 아니라, 작업 플로우 안에서 무료 모델을 보조 엔진으로 안전하게 다루기 위한 구조 정리였다.
`omfm`을 로컬 프록시처럼 두고 진입 경로를 하나로 모으니, 프로젝트 코드는 provider별 분기와 API 키 관리에서 꽤 멀어질 수 있었다.
무료 모델을 작은 역할로 사용하는 것이 아닌 전체적인 작업에 모두 사용하려면 컨텍스트 티어 그룹화를 추가로 진행해야할 필요가 있다.